메모리 관리
by Frinee이 글은 반효경 저 - "운영체제와 정보기술의 원리"를 공부하고 정리하여 작성하였습니다.
1. 주소 바인딩
- 프로그램이 실행을 위해 메모리에 적재될 때 생기는 독자적인 주소공간을 논리적 주소 혹은 가상 주소라고 부름
- CPU는 프로세스마다 독립적으로 갖는 논리적 주소에 근거해 명령을 실행
- 논리적 주소는 각 프로세스마다 독립적으로 할당되며 0번지부터 시작
- 물리적 주소: 물리적 메모리에 실제로 올라가는 위치
- 물리적 메모리의 낮은 주소 영역에는 운영체제가 올라가고 높은 주소 영역에는 사용자 프로세스들이 올라감
- 주소 바인딩(address binding): 프로세스의 논리적 주소를 물리적 주소로 연결시켜주는 작업
1.1. 주소 바인딩 방식
- 프로그램이 적재되는 물리적 메모리의 주소가 결정되는 시기에 따라 분류됨
- 컴파일 타임 바인딩(compile time binding)
- 물리적 메모리 주소가 프로그램을 컴파일할 때 결정되는 방식
- 프로그램이 절대주소로 적재된다는 뜻에서 절대코드를 생성하는 바인딩 방식이라고도 말함
- 프로그램이 올라가 있는 물리적 메모리 주소를 변경하기 위해선 컴파일을 다시 해야 함
- 현대 시분할 방식에선 잘 사용하지 않는 방식
- 로드 타임 바인딩(load time binding)
- 프로그램의 실행이 시작될 때의 물리적 메모리 주소가 결정되는 방식
- 로더(loader)의 책임 하에 물리적 메모리 주소가 부여됨
- 프로그램이 종료될 때까지 물리적 메모리 상의 위치가 고정됨
- 컴파일러가 재배치 가능 코드를 생성한 경우에 가능한 주소 바인딩 방식
- 로더(loader): 사용자 프로그램을 메모리에 적재시키는 프로그램
- 실행시간 바인딩(execution time binding)
- 프로그램이 실행을 시작한 후에도 그 프로그램이 위치한 물리적 메모리 상의 주소가 변경될 수 있는 방식
- CPU가 주소를 참조할 때마다 해당 데이터가 물리적 메모리의 위치를 주소 매핑 테이블을 이용해 바인딩을 점검해야 함
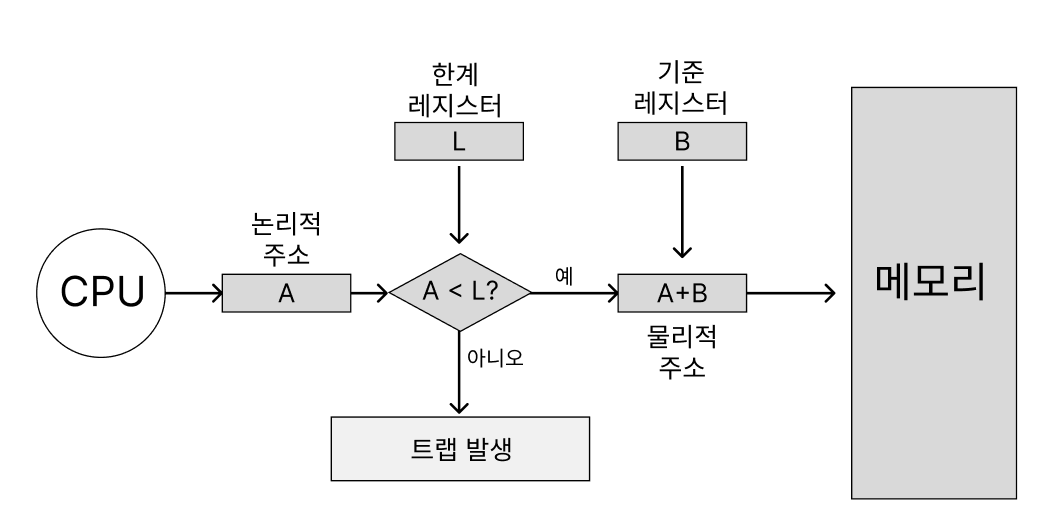
- 기준 레지스터와 한계 레지스터를 포함한 MMU(Memory Management Unit)라는 하드웨어적 지원이 있어야 가능한 방식
1.2. MMU 기법

- CPU가 특정 프로세스의 논리적 주소를 참조하려 할 때 그 주소값에 기준 레지스터 값을 더해 물리적 주소값을 얻어냄
- 이때의 기준 레지스터를 재배치 레지스터라고 부르며 프로세스의 물리적 메모리 시작 주소를 갖고 있음
- 여기선 프로그램의 주소 공간이 물리적 메모리의 한 장소에 연속적으로 적재되는 것을 가정함.
- 프로그램이 적재되는 물리적 메모리상의 시작 주소만 알면 주소 변환을 쉽게 할 수 있음
※ MMU 기법에서 사용자 프로그램이나 CPU는 논리적 주소만 다룸
- 프로세스는 자신만의 고유한 주소 공간을 갖기 때문에 동일한 주소여도 프로세스에 따라 내용이 달라짐
- MMU 기법은 문맥교환으로 CPU에서 수행 중인 프로세스가 바뀔 때마다 재배치 레지스터의 값을 그 프로세스에 해당하는 값으로 재설정해줌
- 여러 프로세스가 동시에 올라가 있는 경우, 다른 프로그램의 영역을 침범할 수 있어 메모리 보안에 문제가 발생
- 이를 방지하기 위해 운영체제는 한계 레지스터(limit register)를 사용하여 자신의 주소 공간을 넘어가는지를 체크.
2. 메모리 관련 용어
2.1. 동적로딩
- 다중 프로그래밍 환경에서 메모리 사용의 효율성을 높이기 위해 사용하는 기법
- 동적로딩에서는 프로세스가 시작될 때 그 프로세스의 주소 공간 전체가 메모리에 올라가지 않고 실행이 필요한 부분만 메모리에 적재하는 방식
- 프로세스 내의 실행이 필요한 부분이 실제로 불릴 때마다 메모리를 적재하는 것을 말함
- 실제 프로그램 코드 중 상당은 오류 처리루틴과 같이 특수한 경우에 가끔 사용되는 방어용 코드
- 그래서 프로세스 주소 공간 전체를 물리적 메모리를 올리는 경우 메모리 낭비가 심해짐
2.2. 동적연결
- 연결(linking): 소스 코드를 컴파일하여 생성된 목적 파일과 라이브러리 파일들을 묶어 하나의 실행 파일을 생성하는 과정
- 동적연결은 목적 파일과 라이브러리 파일 사이의 연결을 프로그램의 실행 시점까지 지연시키는 기법
- 정적연결에서는 코드와 라이브러리 코드가 모두 합쳐져서 실행파일이 생성
- 따라서 실행파일 크기가 크고 동일한 라이브러리를 각 프로세스별로 메모리에 적재하게 되어 메모리 낭비가 심함
- 동적연결은 라이브러리가 실행 시점에 연결되고 실행파일의 라이브러리 호출 부분에 해당 라이브러리를 찾기 위한 스텁(stub) 코드를 둔다.
- 스텁을 통해 해당 라이브러리가 메모리에 존재하는 경우 참조하고,그렇지 않은 경우 디스크에서 동적 라이브러리 파일을 찾아 적재한 후 수행
- 동적연결에서는 다수의 프로그램이 공통으로 사용하는 라이브러리를 한 번만 적재하여 메모리 사용의 효율을 높일 수 있음
2.3. 중첩
- 프로세스의 주소 공간을 분할해 실제 필요한 부분만을 메모리에 적재하는 기법
- 중첩은 초창기의 컴퓨터 시스템에서 물리적 메모리 크기 제약 때문에 단일 프로세스 주소 공간을 분할해서 필요한 부분만 올려서 실행하는 기법에서 시작됨
- 중첩은 운영체제 지원 없이 프로그래머가 직접 구현했고 이런 이유로 수작업 중첩이라고도 부름
2.4. 스와핑
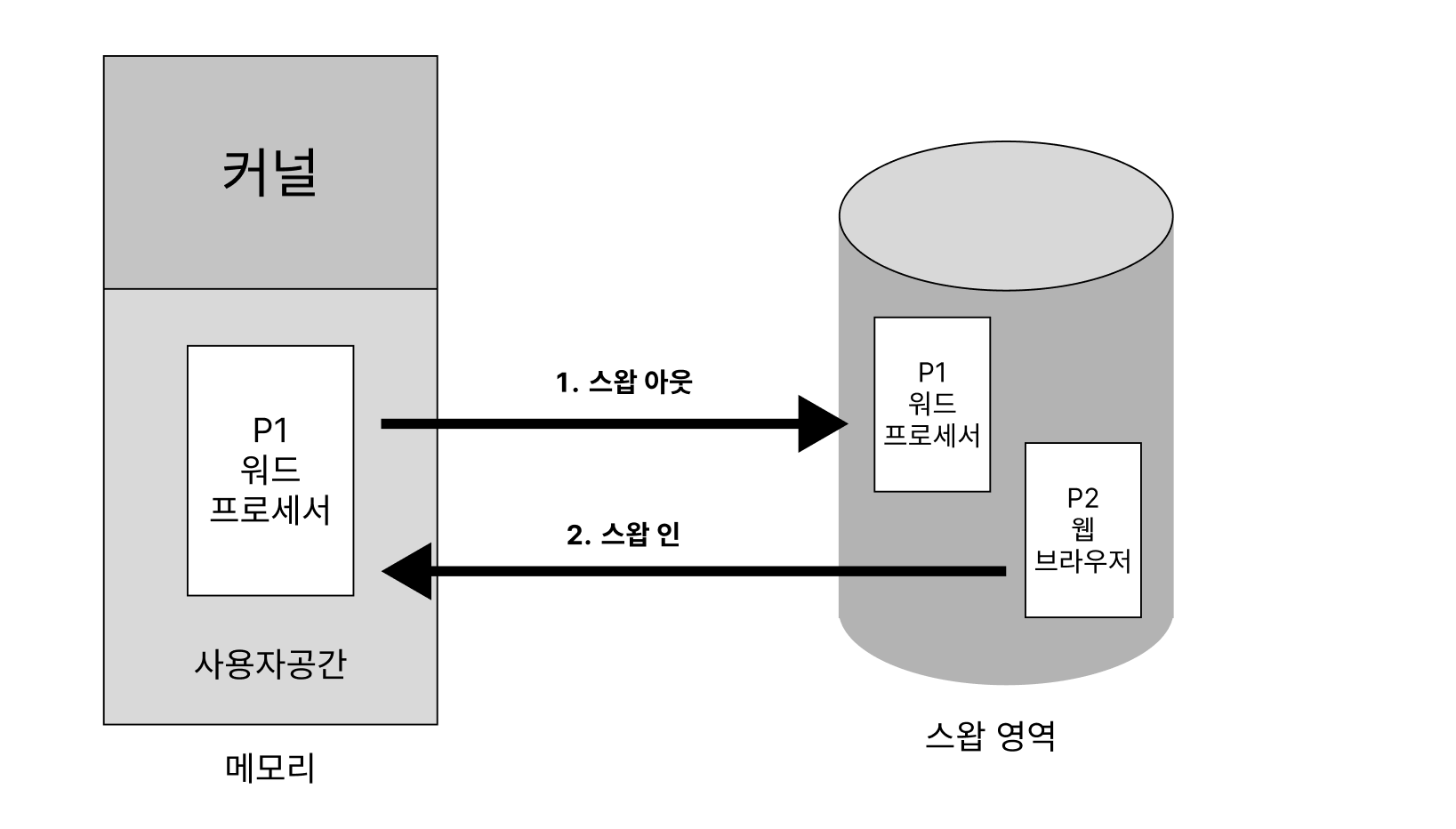
- 메모리에 올라온 프로세스의 주소 공간 전체를 디스크의 스왑 영역에 일시적으로 내려놓는 것
- 스왑 영역(swap area): 혹은 백킹스토어(backing store), 디스크 내의 파일 시스템과는 별도로 존재하는 일정 영역
- 파일 시스템과는 다르게 스왑 영역은 프로세스가 수행 중인 동안에만 디스크에 일시적으로 저장하는 공간
- 스왑 영역은 다수의 사용자 프로세스를 담아야 하기에 충분히 커야하고 접근 속도도 보장되어야 함
- 스와핑은 특정한 이유로 수행 중인 프로세스의 주소 공간을 일시적으로 메모리에서 디스크로 내려놓는 것을 말함.
- 스왑 인(swap in): 디스크 → 메모리
- 스왑 아웃(swap out): 메모리 → 디스크
- 스와핑 과정
- 스와퍼(중기 스케줄러)에 의해 스왑 아웃시킬 프로세스 선정
- 선정된 해당 프로세스는 현재 메모리에 올라가 있는 주소 공간의 내용을 통째로 디스크 스왑영역에 스왑 아웃시킴
- 스와핑의 역할은 메모리에 올라간 프로세스 수를 조절하는 것
- 스왑 아웃된 프로세스를 다시 스왑 인 시키는 경우
- 컴파일 타임 바인딩, 로드 타임 바인딩: 원래 존재하던 메모리 위치에 올려야 함
- 실행시간 바인딩: 빈 메모리 아무 위치나 올릴 수 있음
- 디스크 내의 스왑영역에서 프로세스 주소 공간이 순차적으로 저장됨
- 스와핑 소요 시간은 데이터를 읽고 쓰는 전송 시간이 대부분을 차지함.
3. 물리적 메모리 할당 방식
- 물리적 메모리는 운영체제 상주 영역과 사용자 프로세스 영역으로 나누어 사용
- 운영체제 상주영역
- 인터럽트 벡터와 함께 물리적 메모리의 낮은 주소 영역 사용
- 운영체제 커널이 위치함
- 사용자 프로세스 영역
- 물리적 메모리의 높은 주소 영역을 사용
- 여러 사용자 프로세스들이 적재됨
- 프로세스를 메모리에 올리는 방식에 따라 연속할당 방식과 불연속할당 방식으로 나뉨
3.1. 연속할당 방식
- 각각의 프로세스를 물리적 메모리의 연속적인 공간에 올리는 방식
- 물리적 메모리를 다수의 분할로 나누어 하나의 분할에 하나의 프로세스가 적재됨
- 분할을 관리하는 방식에 따라 가변분할과 고정분할로 나뉨
- 고정분할(fixed partition allocation)
- 물리적 메모리를 고정된 크기의 분할로 미리 나누어두는 방식
- 분할하는 크기는 조절할 수 있고 분할된 공간은 하나의 프로그램만 적재할 수 있음
- 외부조각(external fragmentation): 프로그램의 크기보다 분할의 크기가 작아 비어있는데도 적재하지 못해 발생하는 메모리 공간
- 내부조각(internal fragmentation): 프로그램의 크기가 분할의 크기보다 작아 적재하고 남는 메모리 공간
- 가변분할(variable partition allocation)
- 분할을 미리 나누어 놓지 않은 채 프로그램이 실행되고 종료되는 순서에 따라 분할을 관리하는 방식
- 프로그램의 크기를 고려해서 메모리를 할당하고 관리할 수 있는 기법이 필요
- 메모리에 존재하는 프로그램이 종료될 경우 중간에 빈 공간이 발생하며 이 공간이 새로 시작하는 프로그램보다 작은 경우 외부조각이 발생할 수 있음
- 동적 메모리 할당 문제(dynamic storage-allocation problem): 주소의 공간 크기가 n인 프로세스의 경우 메모리에 올릴 때 어떤 위치에 올릴 지에 대한 문제
- 컴팩션(compaction)
- 물리적 메모리 중에서 프로세스에 의해 사용 중인 메모리 영역을 한쪽으로 몰고 가용 공간들을 한쪽으로 모아 큰 가용공간을 만드는 방법
- 현재 수행 중인 프로세스의 메모리상 위치를 상당 부분 이동시키기에 비용이 많이 듦
- 가급적 적은 수의 메모리 이동으로 효율적인 컴팩션을 수행해야 함
- 이는 프로세스 주소가 동적으로 바뀔 수 있는 실행시간 바인딩 방식에서만 지원
3.2. 동적 메모리 할당 문제
- 최초적합(first-fit)
- 크기가 n 이상인 가용 공간 중 가장 먼저 찾아지는 곳에 할당하는 방법
- 시간적인 면에서 효율적
- 최적적합(best-fit)
- 크기가 n 이상인 가장 작은 가용 공간을 찾아 할당하는 방법
- 크기순으로 정렬되어 있지 않은 경우 모든 공간을 탐색해야 하므로 시간적 오버헤드 발생
- 공간적인 면에서 효율적
- 최악적합(worst-fit)
- 가용 공간 중 가장 크기가 큰 곳에 새로운 프로그램을 할당하는 방법
- 가용 공간 리스트를 탐색해야 하는 오버헤드가 발생
- 더 큰 프로그램을 담을 수 있는 가용 공간을 소모하는 것이 문제
3.3. 불연속할당 방식
- 하나의 프로세스를 물리적 메모리의 여러 영역에 분산해 적재하는 방식
- 페이징(paging) 기법: 각 프로세스의 주소 공간을 동일한 크기의 페이지로 잘라서 메모리에 페이지 단위로 적재시키는 방법
- 세그먼테이션(segmentation) 기법: 프로그램의 주소 공간을 코드, 데이터, 스택 등 의미 있는 단위인 세그먼트로 나누어 적재하는 기법
- 페이지드 세그먼테이션(paged segmentation) 기법: 세그먼트 하나를 다수의 페이지로 구성하는 기법
4. 페이징 기법

4.1. 특징
- 프로세스의 주소 공간을 동일한 크기의 페이지 단위로 나누어 물리적 메모리의 서로 다른 위치에 페이지를 저장하는 방식
- 각 프로세스의 주소 공간 전체를 물리적 메모리에 올릴 필요가 없고 혼재하여 저장이 가능
- 페이징 기법에서는 물리적 메모리를 페이지와 동일한 크기의 프레임으로 미리 나눔
- 메모리에 올리는 단위 = 페이지 단위
- 메모리를 같은 크기로 미리 분할했더라도 빈 프레임이 있으면 어떤 위치든 사용될 수 있음
- 그렇기 때문에 동적 메모리 할당 문제가 발생하지 않는 장점이 있음
- 페이징 기법은 하나의 프로세스라 해도 페이지 단위로 물리적 메모리에 올라가는 위치가 상이함
- 그래서 논리적 주소 → 물리적 주소 변환 작업이 페이지 단위로 이루어져 주소 변환이 복잡함
- 모든 프로세스가 각각의 주소 변환을 위한 페이지 테이블을 갖고 있고 이는 프로세스가 가질 수 있는 페이지 개수만큼 주소 변환 엔트리를 갖고 있음
- 프로그램 크기가 항상 페이지 크기의 배수가 되지는 않기 때문에 제일 마지막에 위치한 페이지는 내부조각이 발생할 수 있음
4.2. 주소 변환 기법

- CPU가 사용하는 논리적 주소를 페이지 번호(p)와 페이지 오프셋(d)으로 나누어 주소 변환에 사용
- 페이지 번호는 페이지 테이블 접근 시 인덱스(index)로 활용
- 인덱스의 항목(entry)은 그 페이지의 물리적 메모리상의 기준 주소, 즉 시작 위치가 저장됨
- 페이지 오프셋은 하나의 페이지 내에서의 변위(displacement)를 알려줌
- 따라서 기준 주소값에 변위를 더하여 논리적 주소에 대응되는 물리적 주소를 구함
4.3. 페이지 테이블 구현
- 페이징 기법에서 주소 변환을 위한 자료구조로 물리적 메모리에 위치함
- CPU에서 실행 중인 프로세스의 페이지 테이블에 접근하기 위해 페이지 테이블 기준 레지스터와 페이지 테이블 길이 레지스터를 사용함.
- 페이지 테이블 기준 레지스터: 메모리 내에서의 페이지 테이블의 시작 위치
- 페이지 테이블 길이 레지스터: 페이지 테이블의 크기 보관
- 페이징 기법에서 메모리 접근 연산은 두 번의 메모리 접근을 필요로 한다.
- 주소 변환을 위해 페이지 테이블에 접근
- 변환된 주소에서 실제 데이터에 접근
4.3.1. TLB(Translation Look-aside Buffer)
- 고속 주소변환용 하드웨어 캐시
- 메모리에 접근 시의 오버헤드를 줄이고 메모리 접근 속도를 향상하기 위해 사용
- TLB로 사용되는 하드웨어는 가격이 비싸 빈번히 참조되는 페이지에 대한 주소 변환 정보만 담음
- 요청된 페이지 번호가 TLB에 존재하면 곧바로 프레임 번호를 얻고, 그렇지 않은 경우 페이지 테이블로 가서 프레임 번호를 얻음
※ 문맥 교환 시 TLB의 이전 프로세스의 주소 변환 정보는 모두 지워짐
- 주소 저장 정보 비교 (페이지 테이블 vs TLB)
- 페이지 테이블
- 하나의 프로세스를 구성하는 모든 페이지에 대한 주소 변환 정보가 페이지 번호에 따라 순차적으로 포함됨
- 페이지 번호가 주어질 시 페이지 테이블에 접근해 프레임 번호를 얻을 수 있음
- TLB
- [페이지번호-프레임번호]가 쌍으로 저장되야 함
- 해당 페이지에 대한 주소 변환 정보를 찾기 위해 전체를 탐색하기 때문에 오버헤드 발생
- 오버헤드를 줄이기 위해 병렬탐색이 가능한 연관 레지스터를 사용
- 페이지 테이블
※ 병렬탐색 기능: 모든 항목을 동시에 탐색할 수 있는 기능
연관 레지스터 사용 시 평균 메모리 접근 시간(Effective Access Time:EAT)
더보기
- 메모리 접근 시간 = 1
- ε: 연관 레지스터 접근 시간
- α: 요청 페이지에 대한 정보가 연관 레지스터에 존재할 확률
$$ EAT = (1+\varepsilon)\alpha + (2+\varepsilon)(1-\alpha) = 2 + \varepsilon - \alpha $$
4.4. 계층적 페이징
- 현대의 컴퓨터는 용량이 커지면서 페이지 테이블 항목도 커짐
- 이로 인한 페이지 테이블에 사용되는 메모리 공간의 낭비를 줄이기 위해 2단계 페이징 기법 사용
- 2단계 페이징 기법에서는 외부 페이지 테이블과 내부 페이지 테이블을 사용
- 사용되지 않는 주소 공간에 대해서 외부 페이지 테이블의 항목을 NULL로 설정하고 여기에 대응하는 내부 페이지 테이블을 생성하지 않으면서 메모리를 절약
- 2단계 페이징 기법을 사용하면 페이지 테이블 생성에 쓰이는 메모리를 절약
- 하지만 주소 변환을 위해 접근해야 하는 페이지 테이블 수가 증가하여 시간적 손해가 생김
4.4.1. 2단계 페이징의 주소 변환
- 프로세스의 논리적 주소를 두 종류의 페이지 번호(P1,P2)와 페이지 오프셋(d)로 구분
- P1: 외부 페이지 테이블 인덱스
- P2: 내부 페이지 테이블 인덱스
- 논리적 주소를 <P1, P2, d>로 표시
- 외부 페이지 테이블로부터 P1만큼 떨어진 위치에서 내부 페이지 테이블의 주소를 얻음
- 내부 페이지 테이블로부터 P2만큼 떨어진 위치에서 요청된 페이지가 존재하는 프레임 위치를 얻음
- 해당 프레임으로부터 d만큼 떨어진 곳에서 원하는 정보에 접근
페이지 번호와 페이지 오프셋을 위한 비트 할당
더보기

- 32비트 주소 체계 시스템
- 페이지 하나의 크기가 4KB
- 페이지 테이블 항목 크기 4Byte
- 프로세스 주소 공간이 커질수록 페이지 테이블의 크기도 커져 메모리 공간 낭비가 커짐
- 그래서 3단계,4단계에 이르는 다단계 페이지 테이블이 필요
- 다단계 페이지 테이블을 사용하면 메모리 공간 소모를 줄일 수 있지만 메모리 접근 횟수가 늘어남
- TLB를 사용하면 다단계 페이징의 공간적 이득과 메모리 접근시간도 많이 늘어나지 않아 시간 효율성도 얻을 수 있음
ex) 연관 레지스터 사용 시 평균적인 메모리 접근시간 계산
더보기
- 다단계 페이징: P = 4
- 메모리 접근시간: M = 100ns
- TLB 접근시간: T = 20ns
- 주소변환정보가 TLB에 존재할 확률: α = 98%
$$ EAT = \alpha \times (M+T) + (1-\alpha) \times [(P+1)\times M + T]\\
= 0.98 \times 120 + 0.02 \times 520 = 128(ns) $$
4.5. 역페이지 테이블
- 메모리 공간 낭비가 심한 이유는 모든 프로세스의 모든 페이지에 대해 페이지 테이블 항목을 다 구성해야 하기 때문
- 역페이지 테이블 기법은 물리적 메모리의 페이지 프레임 당 페이지 테이블에 하나의 항목을 두는 방식
- 즉, 물리적 주소에 대해 페이지 테이블을 만들고 시스템 전체에 페이지 테이블을 하나만 두는 방법
- 페이지 테이블의 각 항목은 프로세스 번호(pid)와 프로세스 내 논리적 페이지 번호(p)를 담고 있음
- 물리적 주소를 활용해 논리적 주소를 얻는 구조이기 때문에 주소 변환 과정은 다소 비효율적
- 주소 변환 요청이 들어오면 해당 페이지가 물리적 메모리에 존재하는지 확인하기 위해 페이지 테이블 전체를 다 탐색해야 함.
- 역페이지 테이블은 일반적으로 연관 레지스터에 보관해 테이블 전체 항목에 대한 병렬탐색을 활용하여 시간을 단축시킴
4.6. 공유 페이지
- 공유 코드(shared code): 메모리 공간의 효율적인 사용을 위해 여러 프로세스에 의해 공통으로 사용될 수 있도록 작성된 코드
- 재진입 가능 코드 혹은 순수 코드라 부리며 읽기전용의 특성을 가짐
- 공유 페이지는 공유 코드를 담고 있는 페이지를 말함.
- 공유 페이지는 여러 프로세스를 물리적 메모리 하나에 적재하여 메모리를 효율적으로 사용하게 함
- 공유 코드는 모든 프로세스의 논리적 주소 공간에서 동일한 위치에 존재해야 하는 제약점이 있음
- 사유 페이지: 프로세스들이 공유하지 않고 프로세스별로 독자적으로 사용하는 페이지(위치 무방)
4.7. 메모리 보호
- 페이지 테이블 각 항목에는 메모리 보호를 위한 보호 비트와 유효-무효 비트를 두고 있음
- 보호 비트(protection bit)
- 각 페이지에 대해 어떠한 접근 권한을 허용하는 지에 대한 정보가 담김
- 각 페이지에 대해 읽기-쓰기/읽기쓰기 전용 등의 접근 권한을 설정하는 데 사용
- 유효-무효 비트(valid-invalid bit)
- 해당 페이지 내용이 유효한지에 대한 내용이 담겨 있음
- 유효(valid): 해당 메모리 프레임에 그 페이지가 존재함, 접근이 허용
- 무효(invalid): 프로세스가 그 주소를 쓰지 않거나 페이지가 물리적 메모리에 없고 백킹스토어에 존재하여 접근 권한이 없음
5. 세그먼테이션
- 프로세스의 주소 공간을 의미 단위인 세그먼트(segment)로 나누어 물리적 메모리에 올리는 기법
- 하나의 프로세스를 구성하는 주소 공간은 일반적으로 코드(code), 데이터(data), 스택(stack) 등의 의미 있는 단위로 구분됨
- 세그먼트는 주소 공간을 기능 단위 또는 의미 단위로 나눈 것을 뜻하고 그래서 크기가 제각각임
- 프로세스의 주소 공간이 나누어져 각각 메모리에 적재되는 특징이 있음
- 크기가 균일하지 않은 세그먼트들은 메모리에 적재하는 부가적인 관리 오버헤드가 발생
- 크기가 제각각이어서 물리적 메모리 관리에서 외부조각이 발생
- 그리고 어느 가용 공간에 할당할 것인지에 대한 문제가 발생함
- 최초적합(first fit): 해당 세그먼트 크기보다 크거나 같은 첫번째 가용공간에 할당
- 최적적합(best fit): 세그먼트의 크기보다 크거나 같은 공간 중 가장 작은 공간에 할당
5.1. 세그먼테이션 기법에서의 주소 변환

- 논리적 주소가 <세그먼트 번호, 오프셋>으로 나뉘어 사용
- 세그먼트 테이블을 사용하여 관리하고 기준점(base)와 한계(limit) 항목을 가짐
- 기준점(base): 물리적 메모리에서 그 세그먼트의 시작 위치
- 한계(limit): 그 세그먼트의 길이
- 세그먼트 길이가 균일하지 않기 때문에 세그먼트 길이 정보를 담고 있어야 함.
- 세그먼트 테이블 기준 레지스터와 세그먼트 테이블 길이 레지스터를 사용함.
- 세그먼트 테이블 기준 레지스터(Segment-Table Base Register: STBR)
- 현재 CPU에서 실행 중인 프로세스의 세그먼트 테이블이 메모리의 어느 위치에 있는지 시작 주소를 담고 있음
- 세그먼트 테이블 길이 레지스터(Segment-Table Length Register: STLR)
- 프로세스의 주소 공간이 총 몇 개의 세그먼트로 구성되는지, 즉 세그먼트 개수를 나타냄
- 세그먼트 테이블 기준 레지스터(Segment-Table Base Register: STBR)
- 확인 사항
- 요청된 세그먼트 번호가 STLR에 저장된 값보다 작은가?
- 논리적 주소의 오프셋 값이 그 세그먼트의 길이보다 작은 값인가?
- 보호비트는 각 세그먼트에 대해 읽기/쓰기/실행 등의 권한을 나타냄
- 유효비트는 각 세그먼트의 주소 변환 정보가 유효한지, 즉 해당 세그먼트가 현재 물리적 메모리에 적재되어 있는지를 나타냄
5.2. 공유 세그먼트
- 여러 프로세스가 특정 세그먼트를 공유해 사용하는 개념을 말함
- 의미 단위로 나누어져 공유와 보안 측면에서 훨씬 효과적임
- 공유하려는 코드와 사유 데이터 영역이 동일 페이지에 존재하는 경우가 발생하지 않음
6. 페이지드 세그먼테이션
- 페이징 기법과 세그먼테이션 기법의 장점만을 취한 방식
- 프로그램을 의미 단위의 세그먼트로 나눔
- 세그먼트를 반드시 동일한 크기 페이지들의 집합으로 구성하고 페이지 단위로 물리적 메모리에 적재함
- 즉, 하나의 세그먼트 크기를 페이지 크기의 배수가 되도록 하면서 외부조각의 문제점을 해결
- 그리고 세그먼트 단위로 프로세스 간 공유나 프로세스 내의 접근 권한 보호가 이루어지도록 하여 페이징 기법의 약점을 해소
6.1. 페이지드 세그먼테이션 주소 변환
- 주소 변환을 위해 외부의 세그먼트 테이블과 내부 페이지 테이블을 둔다
- 세그먼트가 여러 개의 페이지로 구성되므로 각 세그먼트마다 페이지 테이블을 가질 수 있음
- 논리적 주소는 <세그먼트 번호, 오프셋>으로 구성됨
- 논리적 주소의 상위 비트인 세그먼트 번호를 통해 세그먼트 테이블의 해당 항목에 접근
- 세그먼트 항목에는 세그먼트 길이와 세그먼트 테이블 시작 주소가 들어 있음
- 세그먼트 길이값과 논리적 주소 중 하위비트인 오프셋과 비교함
- 만약 오프셋이 더 크면 유효하지 않은 것이므로 트랩 처리
- 그렇지 않은 경우 오프셋 값을 다시 상위/하위 비트로 나눔
- 상위 비트는 그 세그먼트 내에서 페이지 번호로 사용
- 하위 비트는 페이지 내의 변위로 사용
- 상위비트의 페이지 번호를 통해 물리적 메모리의 페이지 프레임 위치를 얻음
- 이 위치에서 페이지 내 변위만큼 떨어진 곳이 바로 원하는 물리적 메모리 주소이다.
자료
- 운영체제와 정보기술의 원리 (반효경 저, 2020.5)
'[컴퓨터 과학자 스터디] > 운영체제' 카테고리의 다른 글
| 디스크 관리 (0) | 2024.11.11 |
|---|---|
| 가상 메모리 (0) | 2024.11.07 |
| CPU 스케줄링 (0) | 2024.10.27 |
| 프로세스 관리 (0) | 2024.10.22 |
| 프로그램의 구조와 실행 (0) | 2024.10.21 |
블로그의 정보
프리니의 코드저장소
Frinee