회복과 병행 제어
by Frinee이 글은 김연희 저 - "데이터베이스 개론 3판"을 공부하고 정리하여 작성하였습니다.
1. 트랜잭션
1.1. 트랜잭션의 개념
- 트랜잭션은 작업 하나를 수행하는 데 필요한 데이터베이스의 연산들을 모아놓은 것으로 데이터베이스에서 논리적인 작업의 단위가 됨.
- 데이터베이스에 장애가 발생했을 때 데이터를 복구하는 작업의 단위도 트랜잭션이다.
- 예시)
- 순서는 상관없지만 두 UPDATE 문이 정상적으로 실행되어야 함.
- 시스템이 정상적으로 작동하게 되어 두 번째 UPDATE 문을 실행해 트랜잭션의 모든 UPDATE문이 정상적으로 실행되거나, 첫 번째 UPDATE문을 취소하여 트랜잭션 작업 전으로 돌려 놓는다.
- 계좌이체 작업
- 성호 계좌에서 5,000원 인출
UPDATE 계좌 SET 잔액 = 잔액 - 5000 WHERE 계좌번호 = 100; - 은경 계좌에 5,000원 입금
UPDATE 계좌 SET 잔액 = 잔액 + 5000 WHERE 계좌번호 = 200;
- 성호 계좌에서 5,000원 인출
- 상품주문 작업
- 새로운 주문 내역 추가
INSERT INTO 주문(주문번호, 주문고객, 주문제품, 주문수량, 주문날짜) VALUES ('o11', 'apple', 'p01', 10, '2022-10-10'); - 주문제품의 재고량 수정
UPDATE 제품 SET 재고량 = 재고량 - 10 WHERE 제품번호 = 'p01';
- 새로운 주문 내역 추가
1.2. 트랜잭션의 특성
⚛️ 원자성
- 트랜잭션을 구성하는 연산들이 모두 정상적으로 실행되거나 하나도 실행되지 않아야 하는 all-or-nothing 방식을 의미함.
- 트랜잭션을 수행하다 장애가 발생하여 완료되지 못할 경우, 지금까지 실행한 연산 처리를 모두 취소하고 트랜잭션 작업 전 상태로 되돌려 넣는다.
🏃🏻♀️ 일관성
- 트랜잭션이 성공적으로 수행된 후에도 데이터베이스가 일관된 상태를 유지해야 함을 의미함.
- 트랜잭션 전 데이터베이스가 일관된 상태였다면 트랜잭션 후에도 또 다른 일관된 상태가 되어야 함.
🛡️ 격리성
- 고립성이라고도 하는데, 현재 수행 중인 트랜잭션이 완료될 때까지 트랜잭션이 생성한 중간 연산 결과에 다른 트랜잭션들이 접근할 수 없음을 의미
- 일반적으로 데이터베이스 시스템은 여러 트랜잭션이 동시에 수행되지만 각 트랜잭션이 독립적으로 수행될 수 있도록 다른 트랜잭션의 중간 연산 결과에 서로 접근하지 못하게 함.
⏳ 지속성
- 트랜잭션이 성공적으로 완료된 후 데이터베이스에 반영한 수행 결과는 어떠한 경우에도 손실되지 않고 영구적이어야 함을 의미
- 시스템 장애가 발생해도 트랜잭션 작업 결과는 없어지지 않고 남아있어야 함.
⚙️ 트랜잭션의 특성을 지원하는 DBMS의 기능
| 트랜잭션의 특성 | DBMS의 기능 |
| 원자성 | 회복 기능 |
| 일관성 | 병행 제어 기능 |
| 격리성 | 병행 제어 기능 |
| 지속성 | 회복 기능 |
1.3. 트랜잭션의 연산
- COMMIT 연산
- 트랜잭션의 수행이 성공적으로 완료되었음을 선언하는 연산
- COMMIT 연산이 실행된 후에야 트랜잭션 수행 결과가 데이터베이스에 반영됨.
- ROLLBACK 연산
- 트랜잭션의 수행이 실패했음을 선언하는 연산
- ROLLBACK 연산이 실행되면 트랜잭션이 지금까지 실행한 연산의 결과가 취소되고 트랜잭션이 수행되기 전의 상태로 돌아감.
1.4. 트랜잭션의 상태

- 트랜잭션은 다섯 가지 상태 중 하나에 속하게 된다.
활동 상태
- 트랜잭션이 수행되기 시작하여 현재 수행 중인 상태
부분 완료 상태
- 트랜잭션의 마지막 연산이 실행된 직후의 상태를 부분 완료라 함.
- 트랜잭션의 모든 연산을 처리한 상태지만 최종 결과를 데이터베이스에 반영하지 않은 상태
완료 상태
- 트랜잭션이 성공적으로 완료되어 commit 연산을 실행한 상태
- 트랜잭션이 수행한 최종 결과를 데이터베이스에 반영하고 데이터베이스가 새로운 일관된 상태가 되면서 트랜잭션이 종료됨.
실패 상태
- 하드웨어나 소프트웨어의 문제, 트랜잭션 내부의 오류 등 여러 이유로 인해 장애가 발생하여 트랜잭션의 수행이 중단된 상태
철회 상태
- 트랜잭션을 수행하는 데 실패하여 rollback 연산을 실행한 상태
- 지금까지 실행한 트랜잭션의 연산을 모두 취소하고 트랜잭션이 수행되기 전의 데이터베이스 상태로 되돌리면서 트랜잭션이 종료
- 철회 상태로 종료된 트랜잭션은 상황에 따라 다시 수행되거나 폐기됨
- 하드웨어 이상이나 소프트웨어 오류인 경우, 다시 수행
- 트랜잭션의 논리적 오류나 처리하려는 데이터가 존재하지 않는 경우, 폐기
2. 장애와 회복
- 회복(recovery): 장애가 발생했을 때 데이터베이스에 장애가 발생하기 전의 일관된 상태로 복구시키는 것
2.1. 장애의 유형
- 시스템이 제대로 동작하지 않는 상태를 장애(failure)라 함.
- 장애의 유형

2.2. 데이터베이스의 저장 연산
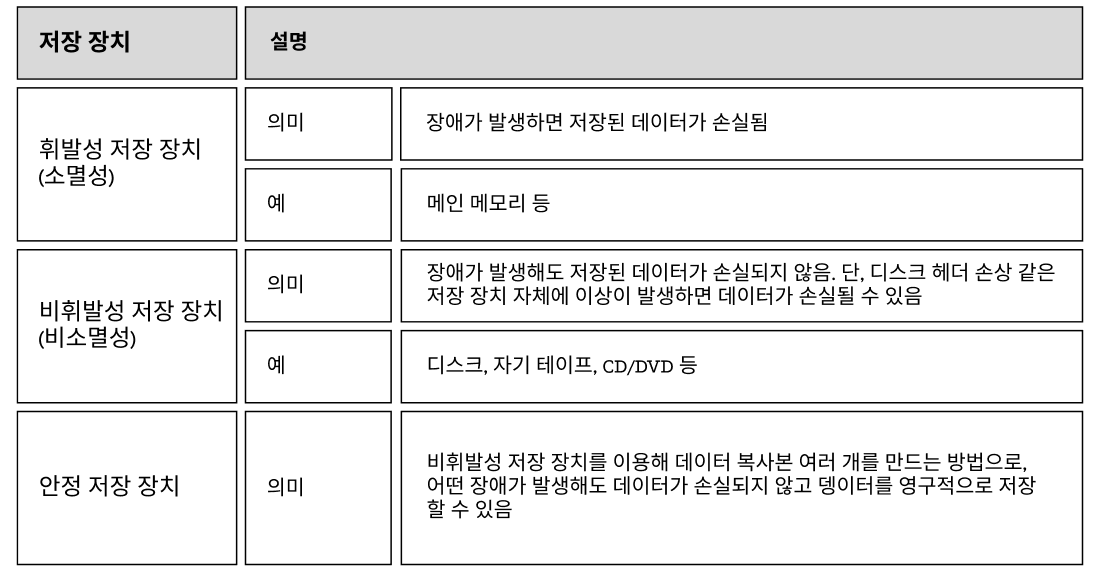
💾 디스크 - 메인 메모리 간 데이터 이동 연산
- 일반적으로 데이터베이스는 비휘발성 저장 장치인 디스크에 상주함.
- 하지만 트랜잭션이 데이터베이스의 데이터를 처리하려면 데이터를 디스크에서 메인 메모리로 가져와 이를 처리한 후 그 결과를 다시 디스크로 보내는 작업을 해야 함.
- 디스크와 메인 메모리 간의 데이터 이동은 대개 블록 단위로 수행됨
- 디스크에 있는 블록을 디스크 블록이라 하고 메인 메모리에 있는 블록 은 버퍼 블록이라 함.
- input(X) : 디스크 블록에 저장되어 있는 데이터 X를 메인 메모리 버퍼 블록으로 이동시키는 연산
- output(X) : 메인 메모리 버퍼 블록에 있는 데이터 X를 디스크 블록으로 이동시키는 연산
📁 메인 메모리 버퍼 블록과 프로그램 변수 간의 데이터 이동 연산
- 사용자의 요구에 따라 응용 프로그램에서 트랜잭션의 수행을 지시하면 메인 메모리 버퍼 블록에 있는 데이터를 프로그램의 변수로 가져옴.
- 그리고 데이터 처리 결과를 저장한 변수 값을 메인 메모리 버퍼 블록으로 옮기는 작업도 수행
- read(X) : 메인 메모리 버퍼 블록에 저장되어 있는 데이터 X를 프로그램의 변수로 읽어오는 연산
- write(X) : 프로그램의 변수 값을 메인 메모리 버퍼 블록에 있는 데이터 X에 기록하는 연산
- 응용 프로그램에 의해 수행된 트랜잭션이 데이터베이스에 접근하여 데이터를 처리할 때 read(X) 연산이 실행됨.
- 계좌이체 트랜잭션
// 성호 계좌에서 5,000원 인출 read(X); X = X-5000; write(X);
2.3. 회복 기법
- 회복은 데이터베이스에 장애가 발생했을 때 장애가 발생하기 전의 모순이 없고 일관된 상태로 복구시키는 것
- 데이터베이스 관리 시스템 내의 회복 관리자가 담당
- 회복 관리자는 장애 발생을 탐지하고, 장애가 탐지되면 데이터베이스 복구 기능을 제공
🏥 회복을 위한 연산
- 데이터베이스 회복의 핵심 원리는 데이터 중복
- 데이터를 별도의 장소에 미리 복사해두고, 장애로 문제가 발생했을 때 복사본을 활용하여 복원
- 덤프 또는 로그 방법을 사용해 데이터를 복사해두었다가 회복시킬 때 복사본을 사용
- dump : 데이터베이스 전체를 다른 저장 장치에 주기적으로 복사하는 방법
- 덤프 방법은 미리 정해진 주기에 따라 수행하고 디스크와 같은 비휘발성 저장 장치에 데이터베이스 복사본을 저장함.
- log : 데이터베이스에서 변경 연산이 실행될 때마다 데이터를 변경하기 이전 값과 변경한 이후의 값을 별도의 파일에 기록하는 방법
- 장애가 발생했을 때, 중복 저장한 데이터를 이용해 데이터베이스를 복구하는 가장 기본적인 방법은 redo나 undo 연산을 실행하는 것
- redo(재실행) : 가장 최근에 저장한 데이터베이스 복사본을 가져온 후 로그를 이용해 복사본이 만들어진 이후에 실행된 모든 변경 연산을 재실행하여 장애가 발생하기 직전의 데이터베이스 상태로 복구
- 전반적으로 손상된 경우에 주로 사용
- undo(취소) : 로그를 이용해 지금까지 실행된 모든 변경 연산을 취소하여 데이터베이스를 원상태로 복구
- 변경 중이었거나 이미 변경된 내용만 신뢰성을 잃은 경우 주로 사용
💬로그를 기록하는 방법
- 로그를 저장한 파일을 로그 파일이라 하는데 로그 파일은 레코드 단위로 기록
- 데이터베이스에 대한 변경 연산은 트랜잭션 단위로 실행되므로 로그 레코드도 트랜잭션의 수행과 함께 기록됨
- 로그는 데이터 손실이 발생하지 않는 저장 장치에 저장
📠로그 레코드의 종류
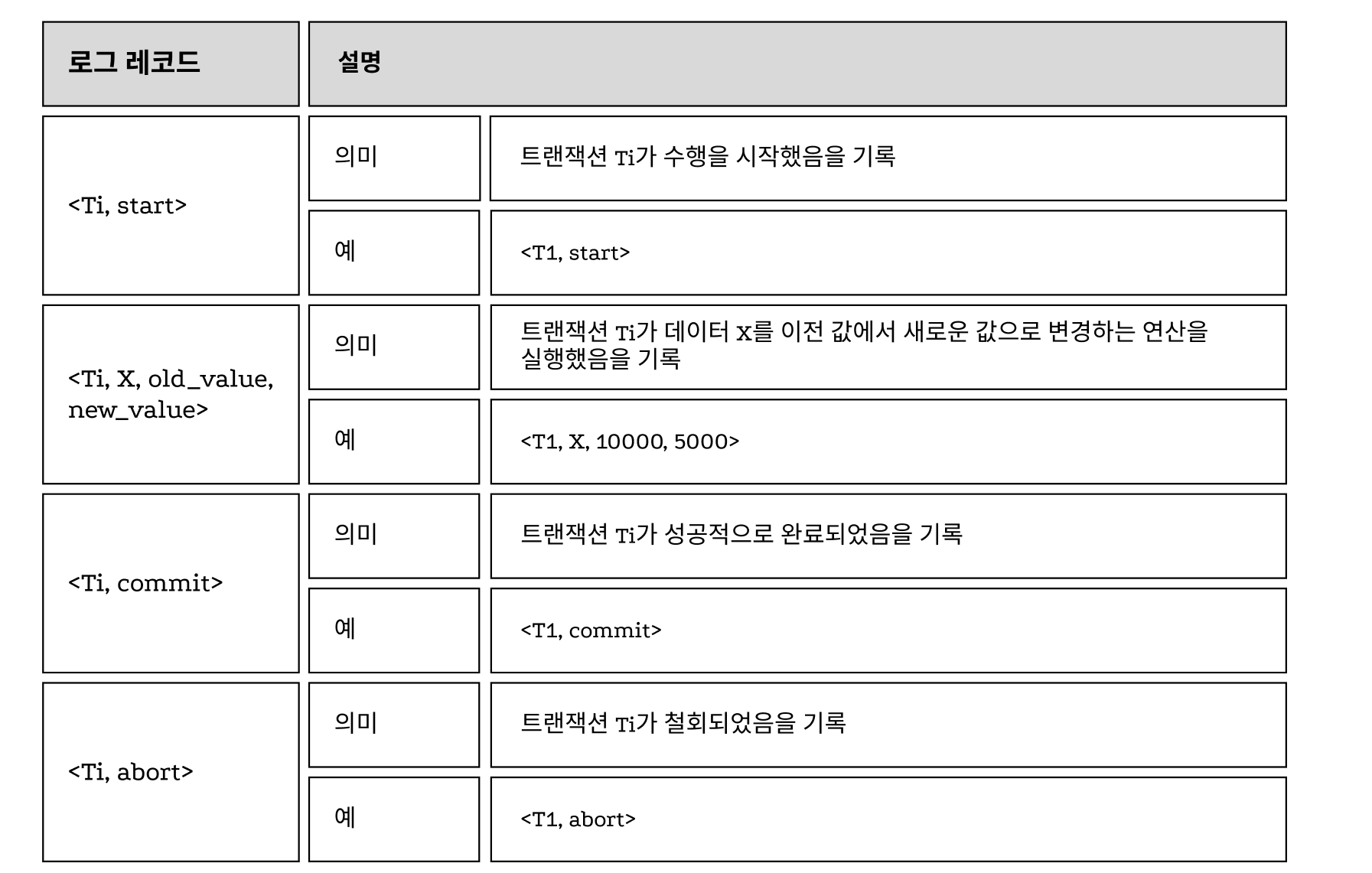
2.3.1. 데이터베이스 회복 기법의 종류
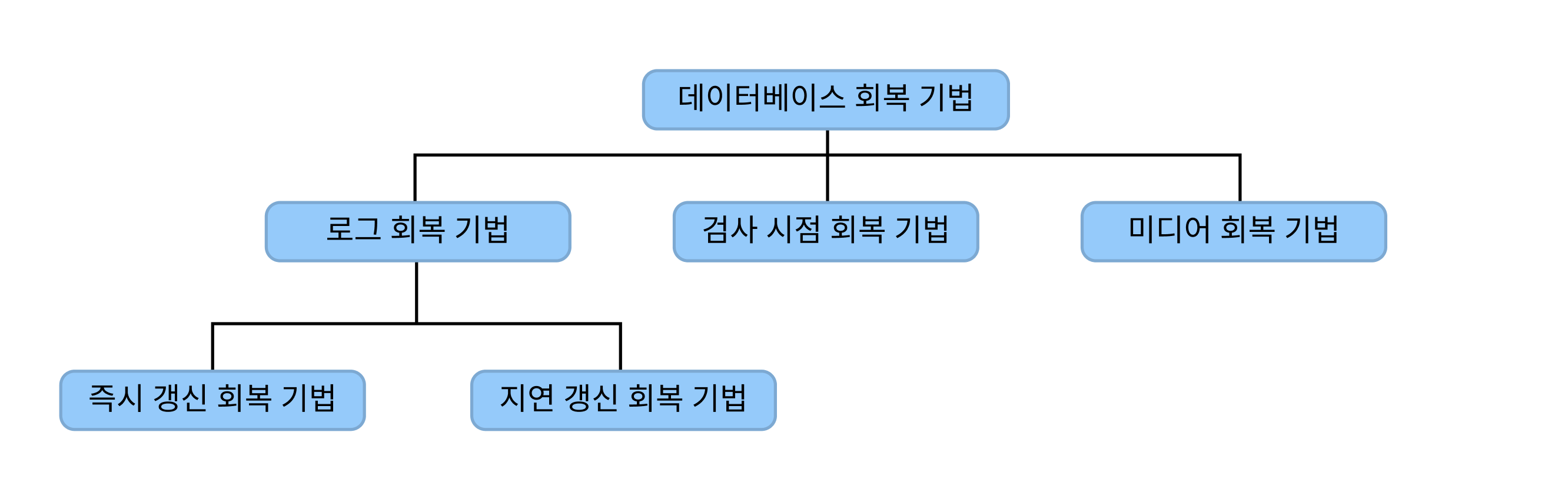
💬로그 회복 기법
- 로그를 이용한 회복 기법은 데이터를 변경한 연산 결과를 데이터베이스에 반영하는 시점에 따라 나뉨
즉시 갱신 회복 기법
- 트랜잭션 수행 중에 데이터를 변경한 연산의 결과를 데이터베이스에 즉시 반영
- 장애 발생에 대비하기 위해 데이터 변경에 대한 내용을 로그 파일에도 기록
- 로그 파일에 로그 레코드를 먼저 기록한 후 데이터베이스에 변경 연산 반영
- 장애가 발생하면 로그 파일에 기록된 내용을 참조하여 장애 발생 시점에 따라 redo나 undo 연산을 실행하여 복구함.
- 트랜잭션 완료 전 장애 발생 → <Ti, commit> 는 없는 상태이고 undo 연산 실행
- 트랜잭션 완료 후 장애 발생 → <Ti, commit> 존재하고 redo 연산 실행
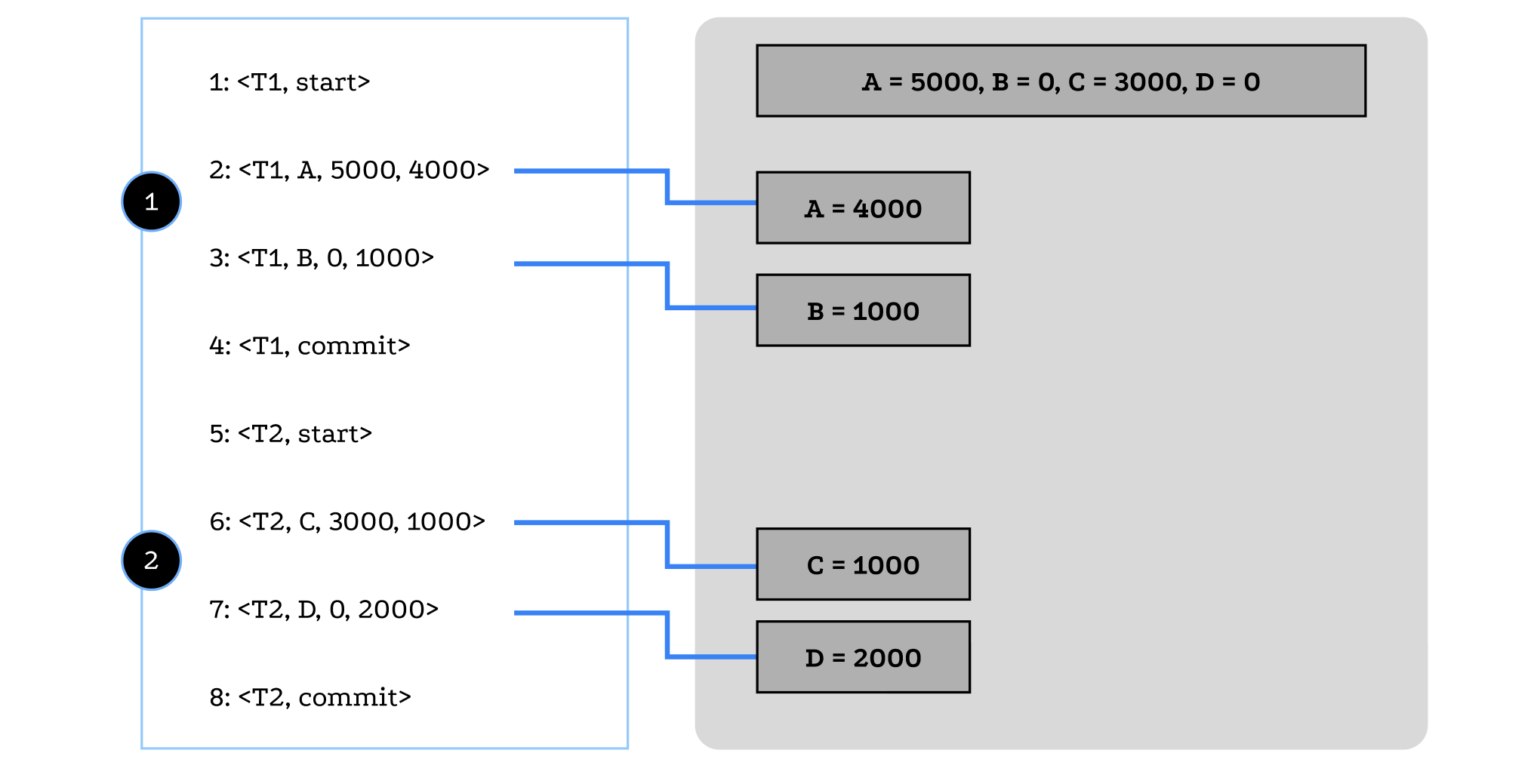
- 1번 시점에서 장애가 발생한 경우
- T1 트랜잭션 수행이 완료되기 전이므로 로그 파일에 <T1, start> 로그 레코드만 존재함.
- 그러므로 T1 트랜잭션에서 undo(T1) 연산을 실행해야 함
- 지금까지 변경한 데이터 값을 변경 연산 이전의 값으로 되돌려야 함.
- 이전 값으로 되돌려야 하는 데이터가 여러 개인 경우 로그에 기록된 순서 반대로 undo 연산 실행
- 2번 시점에서 장애가 발생한 경우
- T1 트랜잭션 수행이 완료되었으므로 <T1, start> 와 <T1, commit> 레코드가 모두 존재함.
- T2 트랜잭션은 완료 전이므로 <T2,start> 만 존재함.
- T1 트랜잭션은 redo 연산을, T2 트랜잭션은 undo 연산을 실행함.
- 둘 다 실행해야 할 땐, T2 undo를 먼저 실행하고 T1 redo를 실행함.
지연 갱신 회복 기법
- 데이터 변경 연산의 결과를 데이터베이스에 즉시 반영하지 않고 로그 파일만 기록했다가, 트랜잭션이 부분완료된 후 데이터베이스에 한 번에 반영
- 트랜잭션이 수행되는 동안 장애가 발생할 경우 로그에 기록된 내용을 버리기만 하면 데이터베이스가 원래 상태를 유지함.
- 지연 갱신 회복 기법에서는 undo 연산은 필요 없고 redo 연산만 필요하므로 변경 이전 값을 기록할 필요가 없음.
- 그래서 변경 연산 실행에 대한 로그 레코드는 <T1, X, new_value> 형식으로 기록됨
- 트랜잭션 완료 전 장애 발생 → 로그 내용 무시하고 버림
- 트랜잭션 완료 후 장애 발생 → redo 연산 실행
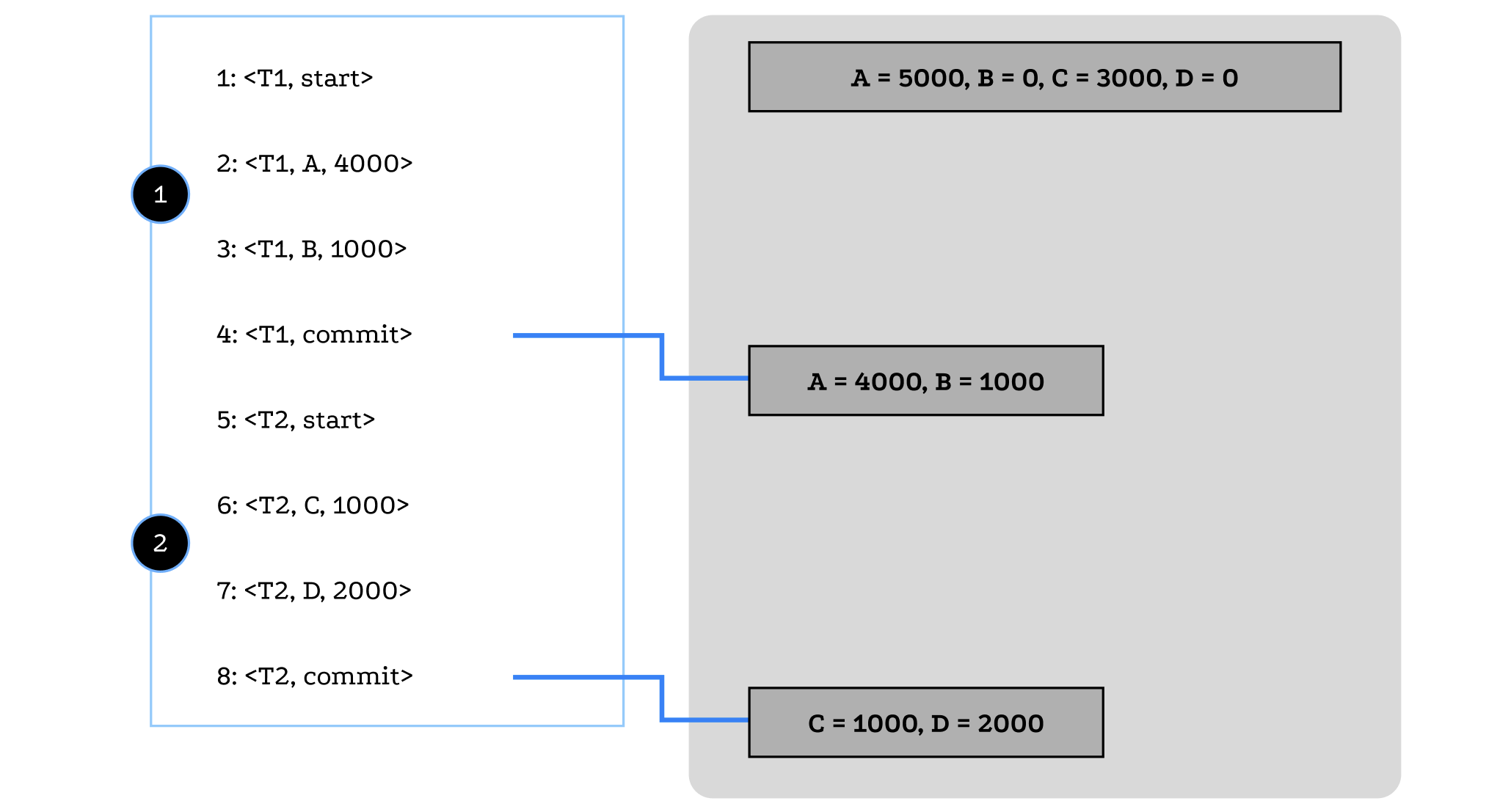
- 1번 시점에서 장애가 발생한 경우
- 로그에 기록된 내용만 버리면 다른 회복 조치가 필요하지 않음
- 2번 시점에서 장애가 발생한 경우
- 완료되지 않은 T2 트랜잭션에 대한 로그 레코드를 무시하고, T1 트랜잭션은 redo(T1) 연산 실행
🔍 검사 시점 회복 기법
- 로그를 이용한 회복 기법은 로그 전체를 분석해서 redo나 undo 회복 연산을 결정해야 함.
- 로그 회복 기법을 적용할 경우, 회복에 너무 많은 시간이 걸리고 비효율적임.
- 검사 시점 회복 기법은 로그 기록을 이용하되, 일정 시간 간격으로 검사 시점을 만들어 둠.
- 그리고 장애가 발생하면 가장 최근 검사 시점 이전의 트랜잭션에는 회복 작업을 수행하지 않고, 이후의 트랜잭션에만 회복 작업을 수행
- 불필요한 회복 작업을 수행하지 않아 데이터베이스의 회복 시간이 단축된다는 장점이 있음
- 일정 시간 간격으로 검사 시점에 메인 메모리에 있는 모든 로그 레코드를 안정 저장 장치에 있는 로그 파일에 기록하고 트랜잭션 데이터 변경 내용을 데이터베이스에 반영
- 그 다음, <checkpoint L> 형식의 로그 레코드를 로그 파일에 기록하고 장애 발생 시 가장 최근의 <checkpoint L> 를 찾아 이후의 로그 기록만 회복 작업 수행
📺 미디어 회복 기법
- 디스크에 발생할 수 있는 장애에 대비한 회복 기법
- 전체 데이터베이스 내용을 일정 주기마다 다른 안전한 저장 장치에 복사해두는 덤프를 이용
- 디스크 장애가 발생하면 가장 최근에 복사해둔 덤프를 이용해 복구하고 필요에 따라 로그 내용을 토대로 redo 연산 실행
- 비용이 많이 들고 복사하는 동안 다른 트랜잭션은 중단되야 하므로 CPU가 낭비되는 단점이 있음
3. 병행 제어
3.1. 병행 수행과 병행 제어
- 데이터베이스 관리 시스템은 여러 사용자가 데이터베이스를 동시에 공유할 수 있도록 여러 개의 트랜잭션이 동시에 수행되는 병행 수행이 지원됨.
- 병행 수행은 실제로 여러 트랜잭션이 차례로 번갈아 수행되는 인터리빙 방식으로 진행
- 병행 수행되는 트랜잭션들이 같은 데이터에 동시에 접근하면 문제가 생길 수 있음
- 여러 개의 트랜잭션이 병행 수행을 하더라도 문제가 발생하지 않고 정확한 수행 결과를 얻을 수 있도록 트랜잭션의 수행을 제어하는 것을 병행 제어 또는 동시성 제어라고 한다.
3.2. 병행 수행의 문제
❗갱신 분실
- 하나의 트랜잭션이 수행한 데이터 변경 연산의 결과를 다른 트랜잭션이 덮어써 변경 연산이 무효화되는 것
- 예) 3000에 1000을 더하는 연산과 반으로 나누는 연산이 병행 수행되면서 뒤에 오는 연산이 덮어서 1500이 되버리는 문제
💁🏻 모순성
- 하나의 트랜잭션이 여러 개의 데이터 변경 연산을 실행할 때 일관성 없는 상태의 데이터베이스에서 데이터를 가져와 연산을 실행함으로써 모순된 결과를 발생하는 것
- 어떤 연산은 현재의 트랜잭션 전 상태의 데이터베이스의 데이터를 가져오고, 또 다른 연산은 다른 트랜잭션이 변경한 데이터베이스의 데이터를 가져와 실행하여 모순이 발생
⛓️ 연쇄 복귀
- 트랜잭션이 완료되기 전에 장애가 발생하여 rollback을 수행하면, 이 트랜잭션이 장애 발생 전에 변경한 데이터를 가져가 변경 연산을 실행한 또 다른 트랜잭션에도 rollback을 수행해야 함.
- 장애가 발생한 트랜잭션이 rollback 연산을 실행하기 전, 변경한 데이터를 가져가 사용하는 다른 트랜잭션이 수행을 완료해버리면 rollback이 불가능해짐.
3.3. 트랜잭션 스케줄
- 트랜잭션 스케줄은 트랜잭션에 포함되어 있는 연산들을 수행하는 순서다.
- 트랜잭션 스케줄의 유형

직렬 스케줄
- 인터리빙 방식을 사용하지 않고 트랜잭션별로 연산들을 순차적으로 실행시키는 것
- 모든 트랜잭션이 완료될 때까지 다른 트랜잭션의 방해를 받지 않고 독립적으로 수행됨
- 직렬 스케줄에 따라 여러 트랜잭션을 수행하면 정확한 결과를 얻을 수 있지만, 각 트랜잭션을 독립적으로 수행하기 때문에 트랜잭션들이 동시에 수행되는 병행 수행이라 할 수 없음.
- → 결론적으로 잘 안써요.
비직렬 스케줄
- 인터리빙 방식을 이용하여 트랜잭션을 병행해서 수행시키는 것
- 하나의 트랜잭션이 완료되기 전 다른 트랜잭션의 연산이 실행될 수 있음
- 갱신 분실, 모순성, 연쇄 복귀 등의 문제가 발생할 수 있어 최종 수행 결과의 정확성을 보장할 수 없음
직렬 가능 스케줄
- 직렬 스케줄에 따라 수행한 것과 같이 정확한 결과를 생성하는 비직렬 스케줄이다.
- 직렬 가능 스케줄은 인터리빙 방식을 이용하여 여러 트랜잭션을 병행 수행하면서도 정확한 결과를 얻을 수 있음
- 대부분의 데이터베이스 관리 시스템에서는 직렬 가능 스케줄인지를 검사하기보다는 직렬 가능성을 보장하는 병행 제어 기법을 사용한다.
3.4. 병행 제어 기법
- 병행 제어 기법은 여러 트랜잭션을 병행 수행하면서도 정확한 결과를 얻을 수 있는 직렬 가능성을 보장받기 위해 사용
- 병행 제어 기법의 기본 원리는 모든 트랜잭션이 따르면 직렬 가능성이 보장되는 나름의 규약을 정의하고, 트랜잭션들이 이 규약을 따르도록 하는 것이다.
🔒 로킹 기법의 개념
- 로킹 기법은 병행 수행되는 트랜잭션들이 동일한 데이터에 동시에 접근하지 못하도록 lock과 unlock이라는 2개의 연산을 이용해 제어함.
- 로킹 기법의 기본 원리는 한 트랜잭션이 먼저 접근한 데이터에 대한 연산을 모두 마칠 때까지, 해당 데이터에 다른 트랜잭션이 접근하지 못하도록 상호 배제하여 직렬 가능성을 보장함.
- lock 연산: 트랜잭션이 사용할 데이터에 대한 독점권을 가짐.
- unlock 연산: 트랜잭션이 데이터에 대한 독점권을 반납함.
- 기본 로킹 규약
- 데이터에 접근하는 연산을 실행하려면 lock 연산을 통해 독점권을 획득해야 함.
- 그러므로 트랜잭션이 데이터에 read 또는 write 연산 실행 전 반드시 lock 연산 실행
- lock 연산을 통해 독점권을 획득한 데이터에 대한 모든 연산이 끝난 후 unlock 연산을 통해 독점권을 반납해야 함.
- lock 연산은 데이터베이스를 구성하는 속성부터 데이터베이스 전체까지 다양한 크기의 데이터를 대상으로 수행 가능함.
- 로킹 단위가 커질수록 병행성은 낮아지지만 제어가 쉽고, 로킹 단위가 작을수록 병행성은 높아지고 제어가 어려워진다.
- 기본 로킹 기법을 사용하면 병행 수행을 제어하는 목표는 이루지만 어떤 순간이든 데이터에 대한 독점권을 하나의 트랜잭션만 가지게 됨.
- 생각해보면 read 연산의 경우, 여러 트랜잭션이 동시에 실행해도 문제가 없음. 그래서 허용하는 것이 효율성을 높일 수 있음
- 공용 lock
- 트랜잭션이 데이터에 대해 공용 lock 연산을 실행하면, 해당 데이터에 read 연산을 실행할 수 있지만 write 연산은 실행할 수 없음
- 해당 데이터에 다른 트랜잭션도 공용 lock 연산을 동시에 실행할 수 있음
- 데이터에 대한 사용권을 여러 트랜잭션이 함께 가질 수 있음
- 전용 lock
- 트랜잭션이 데이터에 전용 lock 연산을 실행하면 해당 데이터에 read 연산과 write 연산을 모두 실행할 수 있음
- 해당 데이터에 다른 트랜잭션은 어떤 lock 연산도 실행할 수 없음
- 전용 lock 연산을 실행한 트랜잭션만 해당 데이터에 대한 독점권을 가질 수 있음
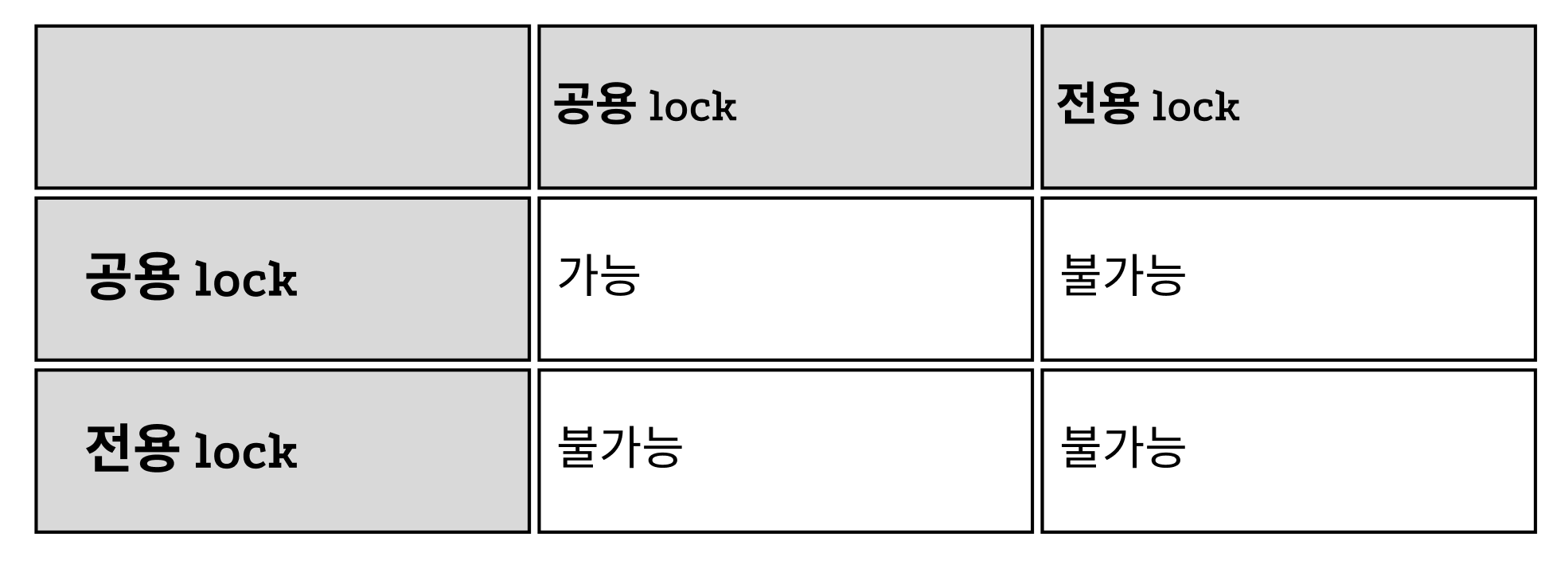
- 하지만 트랜잭션 스케줄 직렬 가능성을 보장하려면 기본 로킹 규약으로는 부족하고 새로운 규약이 추가로 필요함.
🔐2단계 로킹 규약
- 2단계 로킹 규약을 따르려면 모든 트랜잭션이 lock과 unlock 연산을 2단계로 나누어 실행해야 한다.
- 확장 단계: 트랜잭션이 lock 연산만 실행할 수 있고, unlock 연산은 실행할 수 없는 단계
- 축소 단계: 트랜잭션이 unlock 연산만 실행할 수 있고, lock 연산을 실행할 수 없는 단계
- 트랜잭션이 처음에 수행되면 확장 단계로 들어가 lock 연산만 수행할 수 있음
- 이후 unlock 연산을 실행하면 축소 단계로 들어가 그때부터는 unlock 연산만 실행할 수 있음
- 2단계 로킹 규약을 준수하는 트랜잭션은 첫 번째 unlock 연산을 수행하기 전 필요한 모든 lock 연산을 실행해야 함.
- 2단계 로킹 규약을 적용하면 트랜잭션의 스케줄 직렬 가능성을 보장할 수 있음
- 하지만 교착(deadlock) 상태가 발생할 수 있어 해결책이 필요함
- 교착 상태는 트랜잭션들이 상대가 독점하고 있는 데이터에 unlock 연산이 실행되기를 서로 기다리면서 수행을 중단하고 있는 상태
- 교착 상태에 빠지면 상대 트랜잭션이 먼저 unlock 연산을 실행해주기를 한없이 기다리게 됨.
- 교착 상태는 처음부터 발생하지 않도록 예방하거나, 발생했을 때 빨리 탐지하여 필요한 조치를 취하는 방법으로 해결함.
자료
- 데이터베이스 개론 3판 (김연희 저, 2024.1)
'[컴퓨터 과학자 스터디] > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 응용 기술 (1) | 2024.12.05 |
|---|---|
| 보안과 권한 관리 (0) | 2024.12.05 |
| 정규화 (2) | 2024.11.29 |
| 데이터베이스 설계 (2) | 2024.11.27 |
| 데이터베이스 언어 SQL (0) | 2024.11.25 |
블로그의 정보
프리니의 코드저장소
Frinee